
When Cyboticx LLC approached us with an ambitious vision to build an MVP for deep research software that could extract structured data from the internet and organize it into actionable spreadsheets we knew we were embarking on something extraordinary. What started as a straightforward project evolved into a groundbreaking exploration of AI-powered data extraction that would ultimately lead to our proprietary research paper and a completely novel architectural approach.
The Challenge: Beyond Traditional Web Scraping
Cyboticx needed more than just another web scraping tool. They envisioned a system that could understand complex, multi-dimensional queries and return perfectly structured datasets. Imagine asking: "Find all Stanford graduates under 25 doing AI research in San Francisco, including their contact details, current companies, research focus areas, and LinkedIn profiles" and getting back a clean, structured spreadsheet with every data point accurately filled.
This wasn't just about collecting data; it was about understanding context, relationships, and dependencies between different pieces of information.
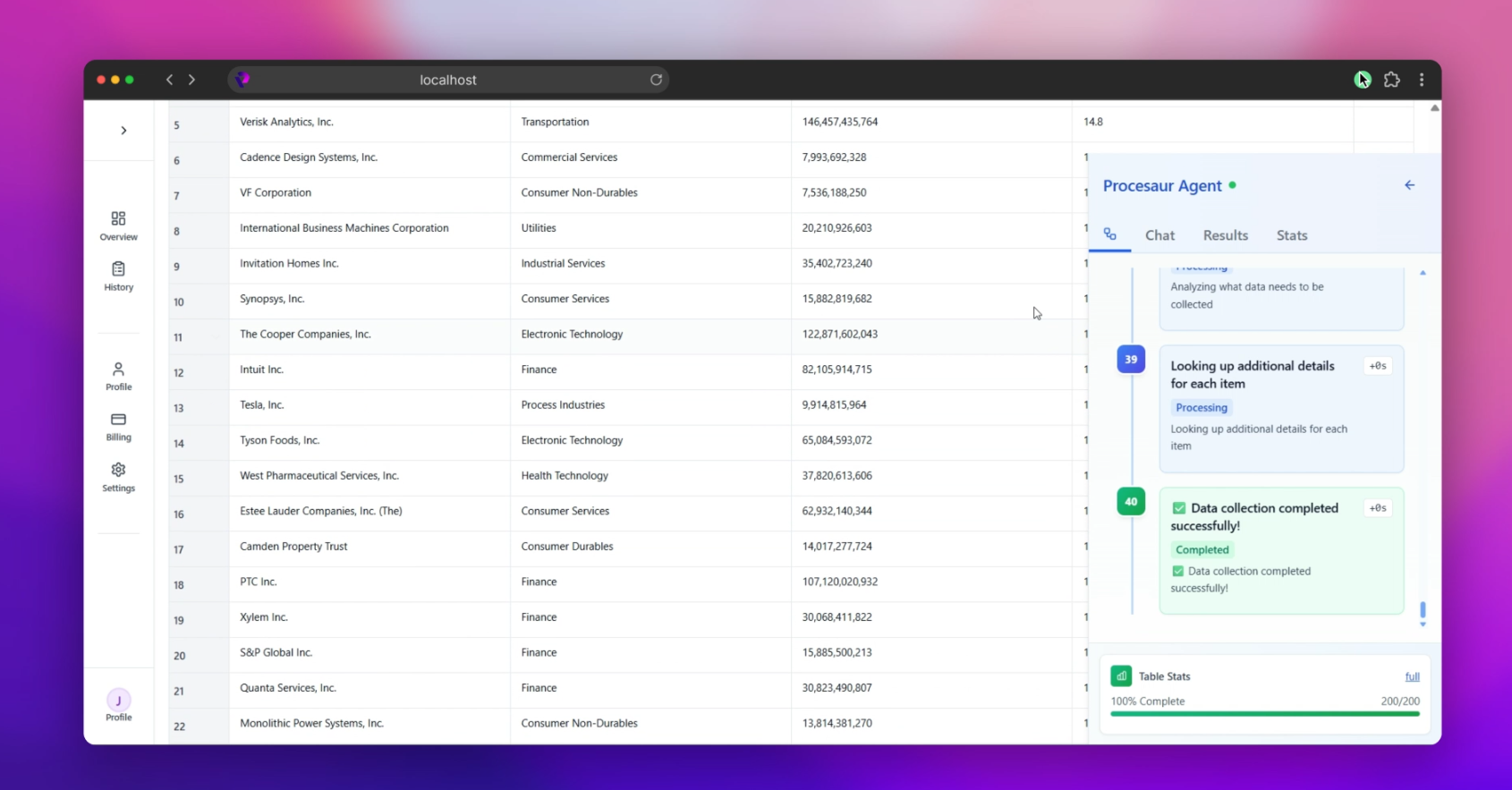
First Attempt: Learning from the Pioneers
Our research led us to Exa.ai, a company that had built something remarkably close to what Cyboticx envisioned. Their Exa Websets tool could handle sophisticated queries like the Stanford graduates example and return structured results with impressive accuracy.
But here's where it got interesting as we dove deeper into understanding Exa's approach, we discovered they had trained their models from scratch using massive internet datasets across multiple GPUs. While brilliant, this approach required significant computational resources and infrastructure investment that simply wasn't feasible for an MVP timeline.
We needed to think differently.
Second Attempt: The Jina.ai Experiment
Our search for alternatives led us to Jina.ai, which offered a fascinating endpoint for extensive web research. Unlike Exa's structured approach, Jina provided a service that would continuously read, scrape, and reason through information until it found the right results. It wasn't specifically designed for structured data, but it showed promise for complex research tasks.
We rolled up our sleeves and built our first MVP using Jina's infrastructure. The results were... encouraging but not quite there. We could get information, but the structure and consistency that Cyboticx needed for their use case remained elusive. The data came back in varying formats, with inconsistent completeness, and required significant post-processing to be truly useful.
Back to the Drawing Board: The Breakthrough Moment
This is where the real innovation began. Instead of trying to adapt existing solutions, we decided to architect something entirely new. During this process, we developed what would become our research paper: "Autonomous Agents for Web Data Extraction via Column-Level Query Decomposition."
The breakthrough came when we reconceptualized the entire data extraction process around two fundamental data types:
Anchor Cells: The Foundation
These are the primary entities that serve as the independent variables of your dataset. In our accounting firms example, the firm names themselves are anchor cells you need to know what you're researching before you can extract attributes about it.
Dependent Cells: The Attributes
These are the specific attributes tied to each anchor cell contact details, review scores, company size, revenue estimates, CEO names, and LinkedIn profiles. Each dependent cell requires the anchor cell as context to be meaningful.
The Architecture That Changed Everything
Our breakthrough architecture worked like this:
Phase 1: Primary Entity Retrieval We deploy a specialized agent to identify all relevant anchor entities. For the query "Find accounting firms in Houston, Texas," this agent focuses solely on discovering and validating the complete list of firms that match the criteria.
Phase 2: Attribute-Based Parallel Extraction Here's where the magic happens. Once we have our anchor entities, we deploy multiple specialized agents in parallel each focused on extracting specific attributes for each entity. This means if we're researching 10 accounting firms with 6 attributes each, we're running 60 targeted, intent-driven queries plus our initial discovery query.
The beauty of this approach lies in its precision. Instead of asking one agent to handle a complex, multi-dimensional query, we break it down into hyper-focused tasks. Each agent becomes an expert at extracting one type of information, leading to dramatically higher accuracy rates.
The Results: From MVP to Market Reality
The transformation was remarkable. Where our previous attempts would return datasets with 60-70% completeness and varying quality, our new architecture consistently delivered 90%+ completeness with structured, clean data ready for immediate analysis.
For Cyboticx's use case, this meant:
- Faster Time to Insights: Clean data eliminated hours of manual cleanup
- Scalable Operations: The parallel architecture could handle datasets of virtually any size
- Higher Accuracy: Specialized agents outperformed generalist approaches consistently
- Flexible Integration: The modular design easily integrated into existing data pipelines
The Technical Innovation
What made this approach particularly powerful was its asynchronous, modular structure. Each query runs independently, which means:
- Fault Tolerance: If one attribute extraction fails, it doesn't impact the others
- Scalability: We can easily add new attributes or entities without restructuring the entire system
- Optimization: Each agent can be fine-tuned for its specific extraction task
- Speed: Parallel processing dramatically reduces total extraction time
Beyond the MVP: Setting New Standards
What started as an MVP for Cyboticx became a proof of concept for an entirely new approach to structured data extraction. The methodology we developed doesn't just solve the immediate problem it establishes a framework that can be adapted across industries and use cases.
Whether you're doing competitive analysis, lead generation, market research, or academic studies, the principle remains the same: break complex data extraction into specialized, focused tasks that can run in parallel for maximum accuracy and efficiency.
The Vellory Difference
This project exemplifies what Vellory brings to complex technical challenges. We don't just implement existing solutions, we dive deep, understand the fundamental problems, and engineer novel approaches that set new standards in the industry.
When faced with the limitations of existing tools, we didn't compromise. We innovated. The result was not only a successful MVP for Cyboticx but also a research contribution that advances the entire field of automated data extraction.
Looking Forward
As AI continues to evolve, the approach we developed for Cyboticx represents a new paradigm in how we think about structured data extraction. By treating each data point as a specialized query and leveraging the power of autonomous agents, we've created a system that scales with complexity rather than being overwhelmed by it.
For businesses looking to harness the power of structured web data, this case study demonstrates that with the right architectural thinking and innovative approach, even the most complex technical challenges can be transformed into competitive advantages.
At Vellory, we specialize in turning complex technical visions into reality. Whether you're looking to build cutting-edge AI systems, innovative data solutions, or groundbreaking software architectures, we bring the expertise and innovative thinking to make it happen.
Ready to build something extraordinary?